On-the-Fly MySQL Response Tracing - Part 1
Ngày 20/10 chúc một nửa thế giới luôn xinh đẹp và tỏa sáng - như ánh đèn Bestlight trong mọi không gian! ✨

Tặng chị em track/reel anh nghiện mấy tuần nay 😎🎶: https://www.tiktok.com/@doanhnhansena/video/7561723932211105031?lang=en
Decrease MTTR (Mean Time To Response) is the most important when we do incident response (IR), it largely depends on the skills and knowledge of the engineers responsible for the system, the more experience and understanding they have, the faster they can resolve issues. But no one can understand all corners of system. Therefore, if we can provide clear insights that help any engineer quickly understand what is happening in the current situation, we can significantly reduce response time and save both time and cost for the organization.
But, how can do that ? That is a very difficult question I thinking about recently, because we met some operate problems in our system, we will take many time to incident response when it happening. That problem is about our database cluster (MySQL) and backends connect to, we don’t know what exactly backend connect to MySQL server, what response my database responsed to the backend when the users told that they can’t access page A,B,C and we couldn’t know how many components have been built in those pages. Just developer/product owner know about it, but how can we proactive it when something wrong happen ?
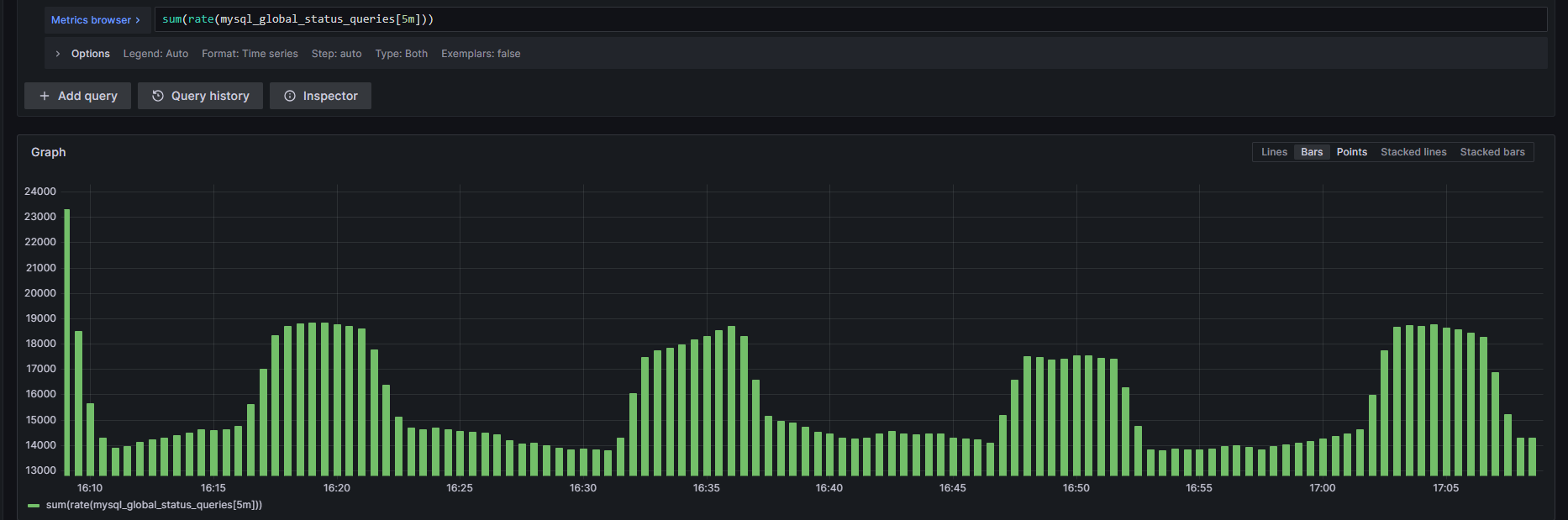
Our MySQL cluster processes approximately 20,000 requests per second - a significant throughput level. Given that 1/3 of Vietnam’s population uses our product, performance considerations are absolutely critical.
Flow:
[Client] <---> [backend] <---> [DB]
Because MySQL legacy doesn’t provide a details what message responsed to the backend in logs or something like this, we can see that at backend level (if developer print it to console), not from database level because this information isn’t available, that makes everything become more hardly to trace.
There is some solutions we can apply in this simple workflow to help “insight” anything we want to know:
- Solution 1: We can integrate some module to our backend to push to centralize somewhere what “insight” we want to know that can read and filter it later.
- Solution 2: Implement more layer between backend and DB help to catch everything happening.
Analysis:
- In solution 1, we need to integrate some logic in backend to do this, that mean we will make more complicated backend and in microservice architechture, that is anti-pattern. Furthermore, if we had many backends these connect to, we need to re-implement it in all of them (or build common-lib that will help decrease a little bit toils), and sure if we need to update something in that module, we need to re-update it in all other backends too.
- In solution 2, we can done it more easily, we can use open-source proxy-style like ProxySQL, adjust config and we can use it immediately with very little toils. Like this:
Flow:
[Client] <---> [backend] <---> [proxy] <---> [DB]
But in solution, we implemented more layer in workflow already. This means, the latency will increase significantly (as there are additional factors to consider, for example network bandwidth, throughput, hardware performance, … affect to latency in this case). With simple thinking, we adding a step in overall workflow -> need more time to do this step. Additionaly, we just want to know what the response responsed to our backend, not by requests or some other one, we will make Over-Engineering. And sure about that we need much more computer resources to implement it. Moreover, if we have very big system that handle million users or billion request per day, latency of each request is one of the most thing we need to consider at. Easily, because we don’t want to make users unhappy because my system is slow of unreliable.
Thus, what is the best solution we can consider in this case?
That is BPF, we can write a BPF program to catch TCP packets that sent before backend received it. In Linux kernel, every message send via TCP proto handled by tcp_sendmsg function. The main tasks we need to consider are “Which deployment methods we will use ?”, “How can we test, experimental and integrate it into our big system ?”. I will write more details about it in next chapter.
[Client] <-- tcp_sendmsg() -- [Server]
^
|
we will hook from here
Have a good day.